


[EP-16] n8n 上的各種 AI 節點功能介紹
本文介紹 n8n 上各種 AI 節點,大略地介紹了AI 模版、AI 代理人、資訊抽取器、問答鏈、情感分析等等節點。文章非常長,慎入。


上次在 EP-14 電子報,我們已經設定了讓公司信件轉寄到 Gmail ,讓 n8n 每日執行來自 Gmail 帶有公司標籤的信件,如果是與長官或同事交辦事項有關,就送到 Notion 。其他的信件則送到 AI 節點做進一步的辨識。
這些 AI 節點,主要是使用 OpenAI、DeepSeek、xAI、Anthropic、Google、Meta 等公司發佈的大型語言模型(LLMs)。
語言模型的功能,目前有下列這幾種,這些功能我們都能運用在 n8n 平台上。
文字處理與生成
輸入與輸出:接受文字輸入(如問題、指令、對話),生成自然語言回應,比如回答問題、撰寫文章、翻譯語言、總結內容等。
對話能力:能進行多輪對話,記住上下文,模擬不同語氣或角色(如專業、幽默、友好)。
程式碼生成:可以生成、解釋或除錯程式碼,支援多種程式語言(如Python、JavaScript等)。
圖像處理與生成
圖像分析:部分模型能分析用戶上傳的圖片,描述內容、識別物體、文字或情緒。
圖像生成:根據文字描述生成圖片(如DALL·E或Midjourney)。
圖像編輯:對之前生成的圖像進行修改(如調整顏色、添加元素)。
聲音處理與生成
語音輸入:一些模型能接受語音訊息,轉錄成文字後處理。
語音生成:將文字轉為語音,模擬自然聲音,甚至模仿特定語調或口音。
聲音分析:辨識語音中的情感、語調或語速。
多模態能力
跨模態轉換:例如,將圖片描述成文字,或根據聲音內容生成圖像,甚至從文字生成音頻故事。
綜合理解:同時處理文字、圖像、聲音等多種輸入,並給出整合的回應。
如何在 n8n 上添加 AI 節點?
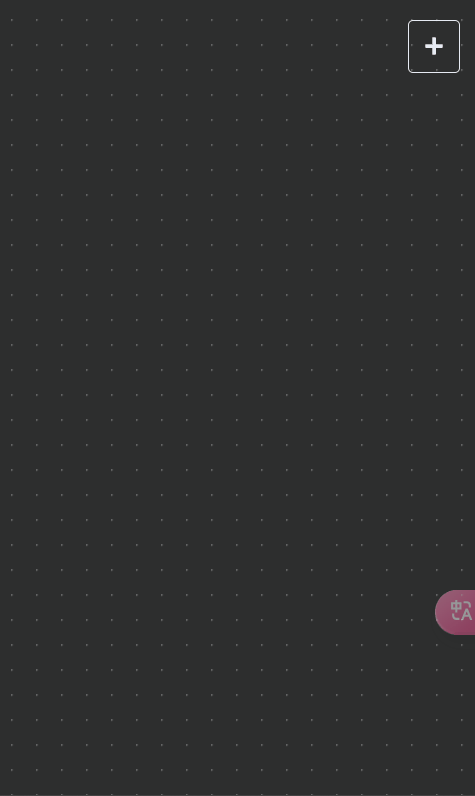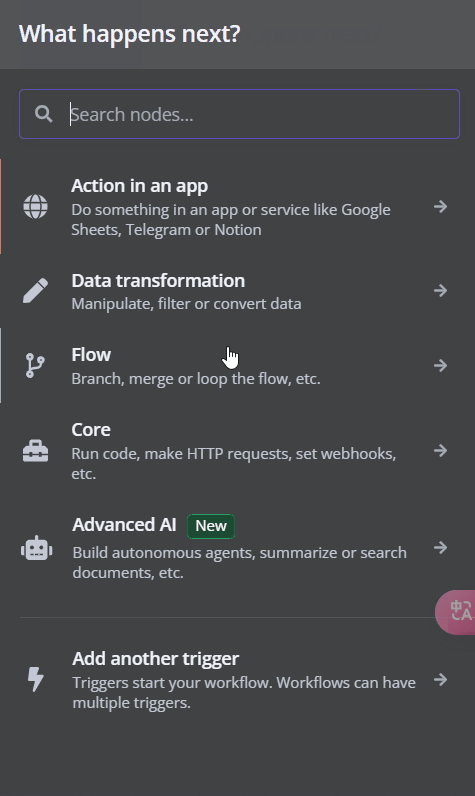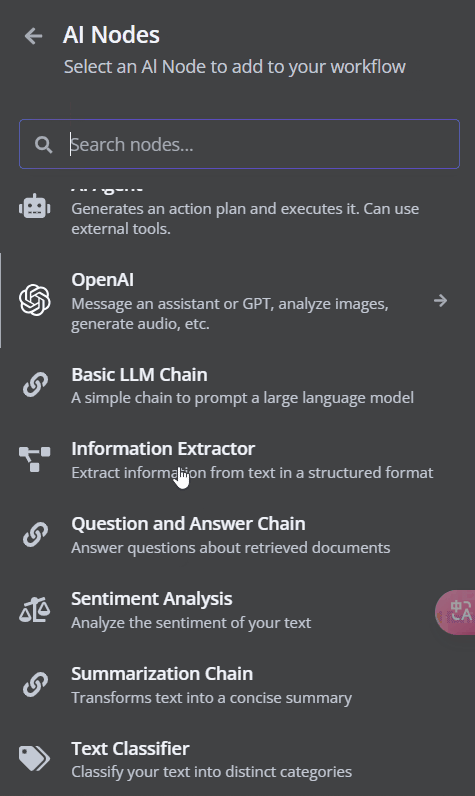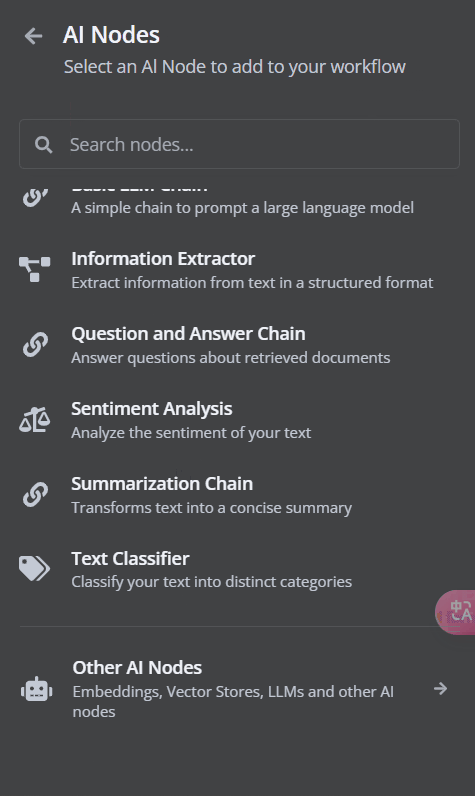
在 n8n 介面上按 + 符號,可以看到 Advanced AI 的選項,點擊 Advanced AI 之後,有下列這幾種選擇:
AI 模版(AI Templates)
AI 代理人(AI Agent)
OpenAI
基礎大型語言模型鏈(Basic LLM Chain)
資訊抽取器(Information Extractor)
問答鏈(Question and Answer Chain)
情感分析(Sentiment Analysis)
總結鏈(Summarization Chain)
文本分類(Text Classifier)
其他 AI 節點(Other AI Nodes)
1. AI 模版(AI Templates)
AI 模版是由眾多網友分享的,點擊後會開啟新視窗,如下圖。
這裡的模版也不只是 AI 模版,而是提供使用者分享他們創作的模版。我很建議新手從模版開始著手,不建議自己手刻。我們可以在這裡尋找一些可用的想法。如果看到適合的模版,大部分都是可以免費使用。
2. AI 代理人(AI Agent)
AI 代理人應該是功能最強大的節點,因此我們必須花最多篇幅說明。
點擊 AI 代理人創建新節點之後,會看到底下的畫面。
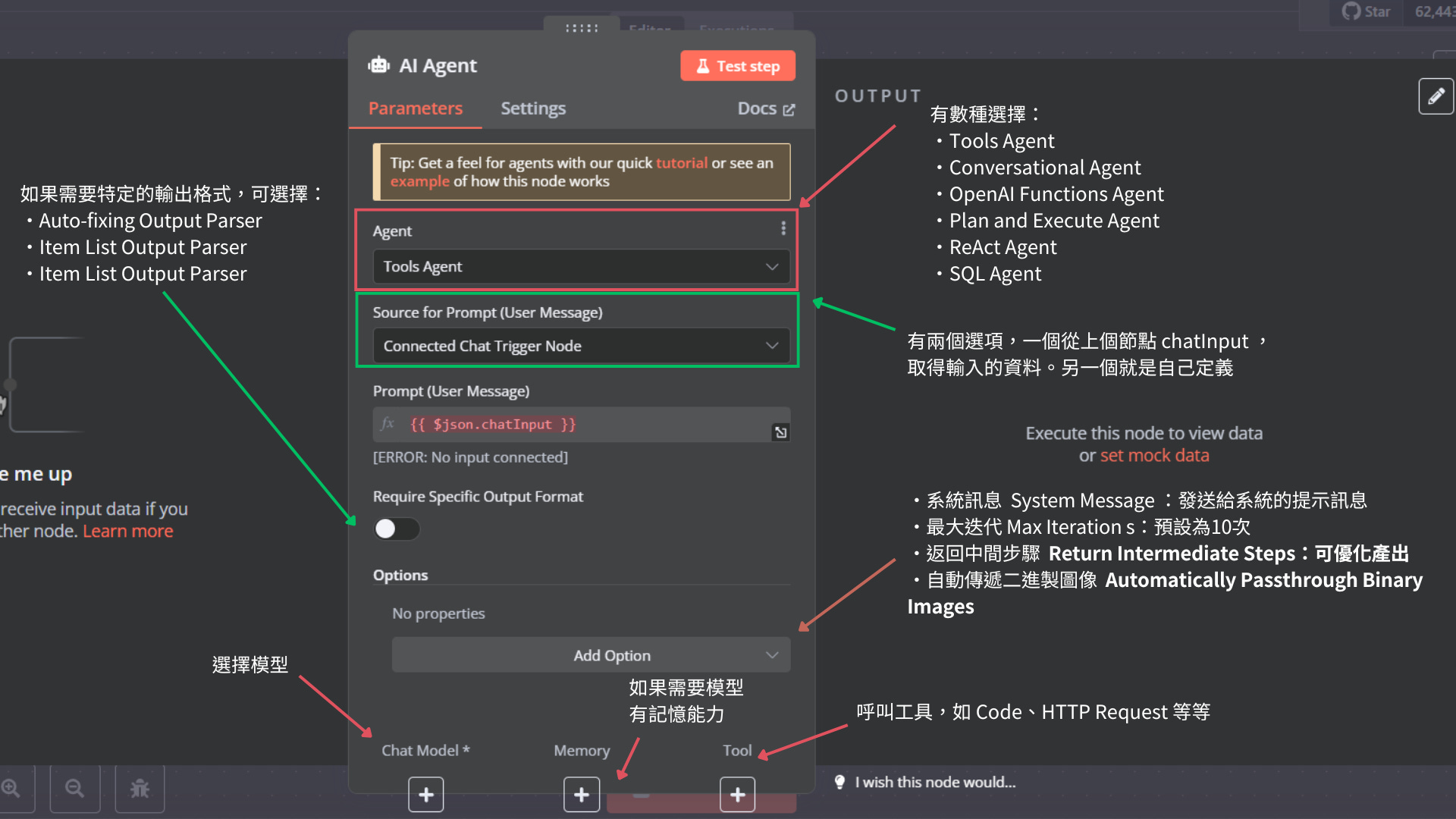
AI Agent 有各種變化型態,在第一個欄位有下拉選單可以選擇,
(1) 工具代理人(Tools Agent)
功能:
結合 LangChain 框架,讓工作流程能夠動態調用多種工具(如 API、資料庫、n8n 工作流)來自動完成複雜任務。
不支援上下文記憶,節點中的 Memory 子節點比較像是提供臨時的記憶,與聊天機器人多次對話的記憶情境不同。
適用情境:
適用於需要自動化且具智慧化決策的情境,例如自動生成報告、資料分析、跨平台資料整合、客服回應、或需多步驟決策的業務流程。
(2) 對話代理人(Conversational Agent)
功能:
支援人性化對話,能理解用戶意圖並保持對話上下文。
適用情境:
適用於需要智能客服、對話式自動化、虛擬助理、或任何需要自然語言互動的應用場景,例如客服機器人、銷售助理、或內部知識問答系統。
(3) OpenAI 功能代理人(OpenAI Functions Agent)
功能:
專為 OpenAI Functions 模型設計,適用於複雜的自然語言理解與生成任務。
適用情境:
適用於需要利用 OpenAI 模型進行複雜資料處理、語言生成、客製化對話體驗、或自動化決策的應用,例如智能客服、內容生成、數據分析報告、或語意分析工具。
(4) 計畫執行代理人(Plan and Execute Agent)
功能:
用於自動規劃並執行多步驟任務。它會先制定計劃,再逐步執行,並根據結果調整後續步驟,以達到高效且智慧化的工作流程管理。
適用情境:
適用於需要多階段決策和動態調整的任務,例如自動化專案管理、複雜工作流排程、策略規劃與執行、或需要即時反饋與調整的業務流程。
(5) 推理與行動代理人(ReAct Agent)
功能:
以推理與行動 (Reason + Act) 的方式進行決策。它能夠根據上下文推理並選擇適當的動作或工具來完成任務,提升任務執行的智慧化和自動化程度。
適用情境:
適用於需要動態決策和複雜推理的應用,例如智能客服、跨系統操作協調、自動化數據處理或策略性決策支持。
(6) SQL資料庫代理人(SQL Agent)
功能:
與 SQL 資料庫互動,能將自然語言轉換為 SQL 查詢,並以易於理解的格式顯示結果。
適用情境:
自然語言查詢生成:例如自動化報表生成、數據分析。
資料洞察提取:從結構化數據中獲取分析結果。
小提示:
Tools Agent 與 OpenAI Functions Agent 的差異在於,Tools Agent 更側重於整合外部工具,而 OpenAI Functions Agent 更適用於自然語言處理與生成。
Conversational Agent 是唯一支援記憶且具備工具整合的選項,因此特別適合用於虛擬助理與聊天機器人。
ReAct Agent 與 Plan and Execute Agent 的差異在於,前者具備動態反應能力,而後者則更注重結構化執行。
3. OpenAI
功能:OpenAI 提供不同模型,主要有底下幾種模式,
助理(Assistant)
文本(Text)
圖像(Image)
音訊(Audio)
檔案(File)
客製化 API (Custom API Call)
用起來其實跟 AI Agent 差不多,只不過這個節點是專門為了 OpenAI 設計的,結合了 LangChain 框架和 OpenAI API,讓工作流程能夠進行自然語言處理、文本生成、資料分析、以及其他 AI 驅動的任務。它支援 GPT 模型,可用於各種語言任務,包括自動回覆、內容生成和語意分析。
適用情境:
適用於需要高度自動化且智能化的應用場景,如客服自動化、行銷內容生成、報告撰寫、數據洞察分析、或語言翻譯工具。
4. 基礎大型語言模型鏈(Basic LLM Chain)
功能:相對來說比較陽春,也沒有記憶功能
適用情境:單純只是需要單次對話的場景。
5. 資訊抽取器(Information Extractor)
功能:根據用戶定義的模板或提示,從文本中提取關鍵資料(如姓名、日期、數字),並且將提取結果轉為 JSON 等結構化格式,便於後續處理。
適用情境:
電子郵件處理:從客戶寄來的詢問郵件中提取訂單號、產品名稱和送貨地址。
社交媒體分析:從 X 貼文中提取用戶提到的品牌名稱、情感傾向或事件時間。
報告自動化:從 PDF 報告中提取關鍵統計資料。
6. 問答鏈(Question and Answer Chain)
功能:結合檢索器(Retriever)和大型語言模型(LLM),從給定的資料中提取相關內容並生成答案。
適用情境:
知識庫查詢:從公司文件、手冊或 FAQ 中回答具體問題,例如「我們的退貨政策是什麼?」
客戶支援自動化:根據內部資料快速回應客戶詢問,如「產品規格有哪些?」
研究與分析:從大量文檔中提取答案,適合學術或商業情報需求。
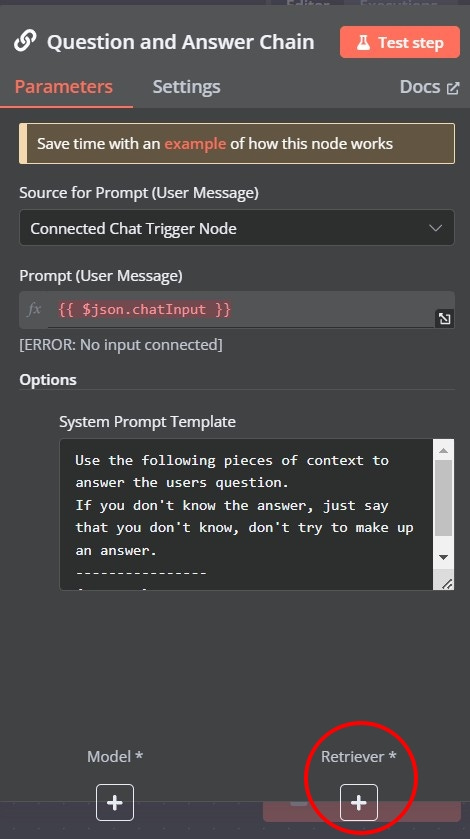
在問答鏈節點設定底下有一個檢索器(Retriever),如上圖。點下去有數種檢索器可供選擇:
(1) 向量資料庫檢索器(Vector Database Retriever)
功能:利用向量資料庫進行相似度搜尋,從大量未結構化資料中找到與查詢最相關的內容。
適用情境:擁有大量文本資料(如文件、文章)且需要根據語意相似度進行高效檢索時,適合使用此檢索器。
(2) 文件檢索器(Document Retriever)
功能:從預先定義的文件集合中檢索相關資訊,通常使用關鍵字匹配或其他傳統搜尋技術。
適用情境:擁有一組已知的文件,且需要根據使用者查詢從中提取相關段落或資訊時。
(3) 知識庫檢索器(Knowledge Base Retriever)
功能:從結構化的知識庫中檢索答案,通常包含 FAQ 形式的資料。
適用情境:適合用於客服系統或常見問題解答,能快速從知識庫中找到精確答案。
(4) 網路檢索器(Web Retriever)
功能:即時從網路上搜尋資訊,獲取最新的資料。
適用情境:當需要查詢最新事件、新聞或動態資訊時,使用此檢索器可以獲得即時結果。
(5) 資料庫檢索器(Database Retriever)
功能:從結構化資料庫中檢索資料,通常使用SQL查詢。
適用情境:當需要從關聯式資料庫中提取特定資訊時,此檢索器非常適合。
7. 情感分析(Sentiment Analysis)
功能:分析傳入文本的情感,例如讓 AI 判斷文本是正面(Positive)、中立(Neutral)、負面 (Negative)。語言模型的溫度要設置為 0 ,確保每次的產出都很穩定。
適用情境:
客戶反饋分析:判斷產品評論或支持票的情感傾向。
社交媒體監控:分析 Threads 貼文或留言的情緒,如品牌聲譽評估。
市場研究:從問卷或訪談中快速識別情感趨勢。
自動化決策:根據情感結果觸發後續動作,如負面反饋提醒客服。
8. 總結鏈(Summarization Chain)
功能:匯總多個文檔,生成簡潔的摘要。
適用情境:
文件摘要:快速總結報告、文章或會議記錄。
新聞監控:從多篇新聞中提取核心內容。
總結鏈另外還分成了不同總結方式,提供三種選項:
(1) Map Reduce
功能:先進行個別段落或片段的摘要(Map),再將所有摘要進行合併與精煉(Reduce)。
適用情境:長篇文章或大型資料集,如技術文件、報告、或多段落內容的總結。
(2) Refine
功能:先生成初步摘要,並在每次新段落加入時進行進一步的精煉。
適用情境:需要在多段內容之間保持連續性和上下文一致性的場合。例如即時會議紀錄或逐步收集的資料總結。
(3) Stuff
功能:將所有內容集中後,一次性進行總結。
適用情境:短篇文章或小型資料集:如簡短的報告、單篇文章、或字數較少的內容。
9. 文本分類(Text Classifier)
功能:顧名思義就是依據文意分類,類別可自行定義。
適用情境:
垃圾郵件過濾:識別電子郵件或訊息是否為垃圾內容。
情感分類:將客戶評論分類為正面或負面(比情感分析更直接)。
內容標籤:為文章或貼文自動標記主題(如科技、健康)。
工作流路由:根據文本類別觸發不同後續動作,如將負面反饋轉給客服。
文本分類節點另外有數個選項可以設定,
(1) 允許多個類別為真(Allow Multiple Classes To Be True)
功能:決定每個項目只能單選(關閉),還是可以多選(開啟)。
適用情境: 當內容可能同時符合多個類別(如多標籤分類)時,建議開啟。
(2) 當無明確匹配時(When No Clear Match)
功能:定義模型無法明確分類時的處理方式,有兩個選項:
丟棄項目(Discard Item):預設選項。
輸出到「Other」分支(Output on Extra, 'Other' Branch):將無法分類的項目輸出到額外的分支,方便後續處理或檢查。
適用情境: 若希望追蹤無法分類的項目,建議使用 "Other" Branch。
(3) 系統提示詞模板(System Prompt Template)
功能:自定義分類過程中的提示詞,以影響模型對內容的理解和分類方式。
適用情境: 當需要針對特定情境或語境進行分類時,可自定義提示詞以提高分類準確性。
(4) 啟用自動修復(Enable Auto-Fixing)
功能:開啟後,當模型輸出的格式不符合預期時,節點會自動修復輸出格式。
適用情境: 當輸出格式需嚴格符合特定要求,或想減少格式錯誤時,建議開啟。
10. 其他 AI 節點(Other AI Nodes)
上述的節點已經可以應付大部分的需求了,但是還有一些少部分的情況,需要使用下面的節點。
(1) 文件加載器(Document Loaders)
負責將文件(例如 PDF、Word 文檔、純文本等)加載到系統中,以便進一步處理或分析。一共有兩種
預設資料加載器(Default Data Loader)
功能:這個選項用於從工作流程中的前一個步驟(previous step)加載資料。它適用於在工作流程內部傳遞和處理已經存在的資料或文件,不需要從外部來源獲取新資料。
適用場景:如果你在前一個步驟已經生成或接收了資料(例如文本、文件內容或結構化資料),這個加載器可以直接使用這些資料作為輸入,繼續後續的處理。
GitHub 文檔加載器(GitHub Document Loader)
功能:這個選項專門用於從 GitHub 平台加載資料或文檔,並將其作為工作流程鏈(chain)的輸入。GitHub 數據可能包括代碼庫、README 文件、問題(issues)、拉取請求(pull requests)或其他與 GitHub 倉庫相關的內容。
適用場景:從 GitHub 倉庫中提取特定文件或資料(例如分析代碼、檢查文檔或整合 GitHub 活動)。
(2) 語言模型(Language Models)
例如用於文本生成、翻譯、問答或語義分析的模型。常見的例子包括基於大規模語言模型的技術,如用於聊天機器人或內容創建的系統。點擊下去有 OpenAI 、 Anthropic 、 Hugging Face 、 Ollama 等語言模型可供選擇。
(3) 記憶(Memory)
管理訊息儲存和檢索的組件,特別是在執行任務或流程時使用。記憶模組可能會記錄上下文、歷史資料或臨時訊息,以便系統能夠在不同步驟之間保持連貫性或進行參考。點擊下去有 Motorhead 、 Postgres 、 Redis 、 Xata 等資料庫儲存方式。 ****
(4) 輸出解析器(Output Parsers)
這是用來確保系統輸出的工具,會將結果格式化或轉換為特定結構或格式。例如,它可以將原始的 AI 輸出整理成表格、JSON 或其他可讀格式,以滿足特定需求。有三種選項:
自動修正輸出解析器(Auto-fixing Output Parser)
功能:這個選項會自動檢測輸出的格式,如果發現不符合預定義的正確格式,會嘗試自動修正或調整輸出。
適用場景:適合用於需要穩定輸出格式的場景,尤其是當上游節點(例如語言模型)可能生成不一致或錯誤格式的資料時。這個解析器可以幫助確保輸出符合期望的結構,減少手動干預。
項目列表輸出解析器(Item List Output Parser)
功能:將結果返回為單獨的項目列表(separate items)。通常以列表或陣列的形式呈現,方便後續處理或迭代。
適用場景:適合需要將資料分拆為多個獨立部分的情況,例如處理多行文本、列表資料或需要逐項操作的結果。這在工作流程中便於與其他節點(如迭代器)集成。
結構化輸出解析器(Structured Output Parser)
功能:將資料返回為定義的 JSON 格式。
適用場景:適合需要以標準化、可機讀格式傳遞資料的場景,例如與 API 交互、資料分析或生成結構化報表。
(5) 檢索器(Retrievers)
用於從資料來源中獲取相關訊息的工具。檢索器可能會搜索資料庫、文件庫或外部資源,找到與當前任務相關的內容。
上下文壓縮檢索器(Contextual Compression Retriever)
功能:通過上下文壓縮技術增強文檔相似性搜索。能夠優化搜索過程,壓縮或過濾不相關的內容,確保返回的結果與查詢的上下文更相關。
適用場景:適合需要從大型文檔集或資料庫中檢索訊息時使用,特別是在自然語言處理或 AI 應用中,需要更精確地匹配查詢與文檔內容的情況。
多查詢檢索器(MultiQuery Retriever)
功能:自動生成多樣化的查詢,它會根據單一查詢生成多個變體或相關查詢,從而覆蓋更廣泛的潛在結果,提高檢索的全面性和準確性。
適用場景:適合需要全面搜索或從多個角度檢索資料的場景,例如在知識庫或文檔庫中查找可能分散的訊息。
向量儲存檢索器(Vector Store Retriever)
功能:使用向量儲存(Vector Store)作為檢索工具,用於高效搜索和匹配相似內容。
適用場景:適合需要基於語義相似性搜索的場景,例如在 AI 應用中檢索與查詢語義相關的文檔或資料。需要與向量數據庫(如 Pinecone、Weaviate 或 FAISS)搭配。
工作流程檢索器(Workflow Retriever)
功能:使用 n8n 的工作流程作為檢索工具,它會利用現有的 n8n 工作流程邏輯來檢索資料。
適用場景:例如從之前的工作流程步驟或外部 API 中提取訊息。
(6) 文本分割器(Text Splitters)
用來將大段文本拆分成較小部分的工具。這種功能在處理長文件或大數據時非常有用,因為它可以使文本更易於分析、管理或傳遞給語言模型。
字符文本分割器(Character Text Splitter)
功能:根據字符數量將文本分割成塊(chunks)。這意味著它會按照指定的字符數(例如每 1000 個字符)將文本切分為多個部分。
適用場景:適合需要簡單、直接分割文本的場景,例如將長文檔按固定長度切分,特別是當文本結構簡單或不需要考慮語義時。
遞歸字符文本分割器(Recursive Character Text Splitter)
功能:通過遞歸的方式根據字符數量將文本分割成塊,並針對大多數使用場景推薦使用。它會嘗試按層次結構(例如段落、句子或單詞)逐步分割文本,直到達到指定的字符數限制,這樣可以保留更多的上下文和結構完整性。
適用場景:適合大多數文本處理場景,尤其是需要保留文本語義和結構的情況,例如 AI 模型輸入、長文檔分析或需要避免單詞中斷的場景。因為它是“推薦用於大多數使用場景”的,所以通常是預設或最常用的選擇。
標記分割器(Token Splitter)
功能:根據標記(tokens)將文本分割成塊。標記通常是語言模型或分詞器識別的基本單位(例如單詞、標點符號或子詞),而不是簡單的字符數。也就是說,分割會考慮文本的語義和語言結構,而不是僅依賴字符數。
適用場景:適合需要與語言模型或自然語言處理(NLP)工具集成的場景,例如將文本準備為 AI 模型的輸入(因為許多模型輸入限制是以標記為單位)。這在處理多語言文本或需要精確控制語義分割時非常有用。
(7) 工具(Tools)
提供各種功能的實用模組,可能包括資料處理、格式轉換、API 集成或其他特定任務的工具,用於增強工作流程的靈活性。點擊下去有各家廠商的工具, 底下只介紹最常用的:
調用 n8n 工作流程工具(Call n8n Workflow Tool)
功能:將現有的 n8n 節點或工作流程封裝為一個工具,允許你將其作為單獨的工具在工作流程中使用。
適用場景:適合需要重用或封裝現有 n8n 工作流程的場景,例如在多個工作流程中重複使用相同的邏輯或功能。
代碼工具(Code Tool)
功能:允許你使用 JavaScript 或 Python 撰寫自定義工具。
適用場景:適合需要高度自定義或無法通過現有 n8n 節點實現的場景。
HTTP 請求工具(HTTP Request Tool)
功能:發送 HTTP 請求並返回資料,可以與外部 API 或網站通訊,獲取資料、發送資料或執行其他基於 HTTP 的操作。
適用場景:適合需要與外部服務或 API 集成的場景,例如從 REST API 獲取資料、發送 POST 請求或檢查網站狀態。
(8) Embeddings(嵌入)
嵌入是一種將文本(如單詞、句子或段落)轉換為數學向量(通常是多維數組)的技術,這些向量可以捕捉文本的語義和語境,常用於自然語言處理(NLP)和機器學習模型。
(9) 向量儲存(Vector Stores)
提供向量資料庫,通常與嵌入(Embeddings)一起使用,以實現基於語義的搜索或資料檢索。包括 Pinecone、Postgres、Qdrant 等。
(10) Miscellaneous(雜項)
其他與 AI 相關的節點,包含各種不屬於上述類別的 AI 功能或工具。包含下列三種:
OpenAI
前面介紹過了,不贅述。
聊天記憶管理器(Chat Memory Manager)
功能:管理聊天消息的記憶,並在工作流程中使用。這意味著它可以儲存、檢索和處理聊天歷史或會話資料,確保上下文在工作流程中保持連貫。
適用場景:適合需要跟踪會話歷史或上下文的場景,例如聊天機器人。
LangChain 程式碼(LangChain Code)
功能:上述這些節點都是基於 LangChain 框架,如果要客製化可以用這個節點。
適用場景:適合需要自定義 AI 邏輯的場景,例如將多個 AI 模型(如 OpenAI、嵌入模型)串聯起來,實現問答系統、文件摘要或代理式 AI 應用。
Thx.
很詳細,謝謝分享